
SUMMARY
This platform combines Federated Machine Learning and Privacy Preserving Machine Learning disciplines to provide scalable and robust privacy over different privacy scenarios commonly found in data-driven industrial applications. The platform provides a set of configurable “Privacy Operation Modes” (POMs) in which the platform operates and a library with a full set of machine learning algorithms efficiently implemented on a federated manner under the assumptions of each POM.
Motivation
Training models with data from different contributors is an appealing approach, since when more and more data are used, the performance of the resulting models is usually better. A centralised solution requires that the data from the different users is gathered in a common location, which is not always suitable due to privacy/confidentiality restrictions. Our innovative platform aims at solving Machine Learning (ML) problems on distributed data, preserving the privacy/confidentiality of the data and/or the resulting models. Essentially, it aims at deploying a distributed ML setup (Fig. 1) such that a model equivalent to the one obtained in the centralised setup is obtained.
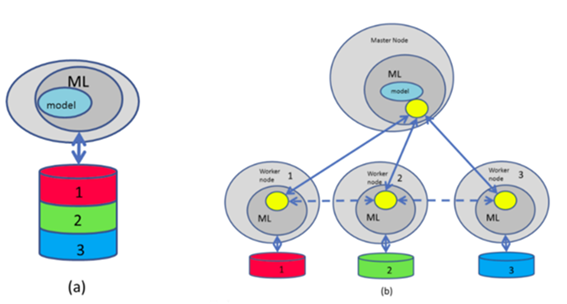
Figure 1. Centralised approach (a) vs our privacy preserving distributed scenario (b) where every user provides a portion of the training set
FML Architecture
Federated Machine Learning (FML) allows different devices to collaboratively learn a shared prediction model while keeping all the training data on each device, decoupling the ability to do machine learning from the need to store the data in the cloud. The concept of FML can be implemented in different distributed architecture styles. Our implementation is based on a client-server option, built on top of a “star” network topology consisting of the following elements:
The figure below presents a schematic view of the system for a network:
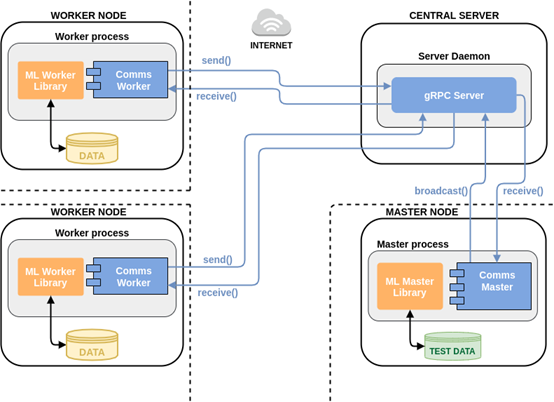
Figure 2. FML Architecture
Federated Machine Learning Library (FMLL)
In TREE’s Federated Machine Learning Library (FMLL) we foresee different possible Privacy Operation Modes (POMs) with different assumptions/characteristics. In what follows, we briefly describe each of the implemented POMs, each one offering a variety of machine learning models/algorithms, always respecting the privacy restrictions defined by the specific POM. As indicated, the Master is the central object or process that controls the execution of the training procedure and the Workers or participants run at the end user side as the platform clients, and they have a direct access to the raw data provided by each participating node.
POM 1
This POM is designed for scenarios where the local datasets at each node are privacy-protected, but the final trained model is not private. At the end of the training cycle, every worker node and the master node would share a copy of the model.
This POM implements a federated-learning framework based on the concept introduced by Google in 2016 (Konečný et al. 2016a). Under this paradigm (Yang et al., 2019), a shared global model is trained under the coordination of the central node, from a federation of participating devices (nodes). It enables different devices to collaboratively learn a shared prediction model while keeping the training data always locally on device, decoupling the ability to perform machine learning from the need to centralise and store the data in the cloud. Using this approach, different data owners can jointly train a predictive model without being their data transferred, exposing it to leakage or data attacks. In addition, since the model updates are specific to improving the current model, there is no reason to store them on the server once they have been applied.
Any model trainable by gradient descent or model averaging (Kamp et al., 2019) can be deployed under this scheme. Since the model is not private, every worker and the central node will receive it at every iteration. The algorithms developed under this POM conform to the following steps: (1) The aggregator defines the model, which is sent to every worker. (2) Every participant computes the gradient of the model or updates the model (for a model averaging schema) with respect to his data and sends aggregated gradient or the model back to the aggregator, which joins the contributions from all participants and updates the model. (3) This process is repeated until a stopping criterion is met. Under this POM the model is sent to the workers unencrypted and the workers send an averaged gradient vector/updated model to the aggregator.
POM 2
The work proposed in (Phong et al., 2018) shows that having access to the predictive model and to the gradients it is possible to leak information. Since the orchestrator has access to this information in POM1, if it is not completely under our control (e.g. Azure or AWS cloud), POM2 would solve the problem by protecting the gradients over the honest-but-curious cloud server. This POM implements the Federated Machine Learning (FML) paradigm described in POM1 but adding homomorphic encryption (Yi et al., 2014) to preserve model confidentiality from the central node. All gradients are encrypted and stored on the cloud and the additive property enables the computation across gradients. This protection comes with the cost of increased computational and communication between the learning participants and the server.
At the end of the training stage the model is known by all the workers but not by the aggregator. In this POM all the participants use the same pair of public/private keys for encryption/decryption. The aggregator has access to the public key but not to the private one, meaning that it cannot have access to the data encrypted by the workers. It comprises the following steps: every worker has the same pair of public/private keys, the public key is shared with the aggregator, which defines the model and encrypts it. The encrypted model is sent to every participant, which decrypts it with the private key and computes the gradients. Then, it sends back to the master the encrypted computed gradients. Finally, the aggregator averages the received gradients and updates the local copy of model weights in the encrypted domain thanks to the homomorphic encryption properties. In this case the model is sent to the workers encrypted, the workers send encrypted gradient vector/updated model to the aggregator, which updates the model in the encrypted domain with no possibility of decryption.
POM 3
In POM2, every data owner trusts each other and they can share the private key of the homomorphic encryption (e.g. different servers with data that belongs to the same owner). Using the same key, every data owner uses the same encrypted domain. In many situations this is not a suitable approach. POM3 is an extension of POM2 that makes use of a proxy re-encryption (Fuchsbauer et al. 2019) protocol to allow that every data owner can handle her/his own private key (Hassan et al., 2019).
The aggregator has access to all public keys and is able to transform data encrypted with one public key to a different public key so that all the participants can share the final model. The learning operation under this POM is as follows: every worker generates a different key pair randomly and sends the public key to the aggregator, which defines the initial model, such that it is sent unencrypted to every participant. Here the model is sent to every worker in its own encrypted domain in a sequential communication, the workers send encrypted gradient vector/updated model to the aggregator and the aggregator updates the model in the encrypted domain and uses proxy re-encrypt techniques to translate among different encrypted domains.
Algorithms
Our FMLL library implementations several ML algorithms specifically for the federated setup over the different POMs. The library contains algorithms capable to infer functions of different nature:
ACKNOWLEDGEMENTS
These developments have been performed under MUSKETEER project (CORDIS page). This project has received funding from the European Union’s Horizon 2020 research and innovation programme under grant agreement No 824988.
These developments have been performed under PRIMAL project. This project has received funding from the European Union’s Horizon 2020 research and innovation programme under grant agreement No 825618.

This site was made with Mobirise templates